Manuscript OCR
Manuscript OCR – отечественная открытая инфраструктура полного OCR/HTR-пайплайна для распознавания дореформенных рукописей на русском языке XVIII–XIX веков и современных текстов.

Описание
Manuscript OCR – отечественная открытая инфраструктура полного OCR/HTR-пайплайна для распознавания дореформенных рукописей на русском языке XVIII–XIX веков и современных текстов. Проект направлен на цифровизацию и анализ исторического текстового наследия с использованием разработанных методов, учитывающих устаревшую орфографию, сложную структуру страниц и вариативность почерков, и обеспечивающих высокую вычислительную эффективность на ограниченных ресурсах.
Фреймворк включает 8 специализированных OCR/HTR-моделей, обученных на собственном одном из крупнейших открытых русскоязычных датасетов: более 250 тыс. реальных и более 2 млн. синтетических изображений словоформ.
Экономический и практический эффект
Manuscript OCR автоматизирует один из самых трудоёмких этапов цифровизации архивов — ручную расшифровку исторических документов.
Среднее время обработки одной страницы сокращается с 5-10 минут ручной транскрипции до менее 1 минуты полного OCR-цикла с постобработкой.
Это позволяет:
ускорить обработку архивных фондов в 8–10 раз;
сократить трудозатраты до 85%;
существенно снизить стоимость оцифровки исторических документов;
повысить доступность архивных материалов для исследователей и образовательных организаций.
Производительность системы:
до 1000 слов/сек на GPU;
до 100 слов/сек на CPU;
около 5 секунд на обработку архивной страницы.
Пайплайн решения
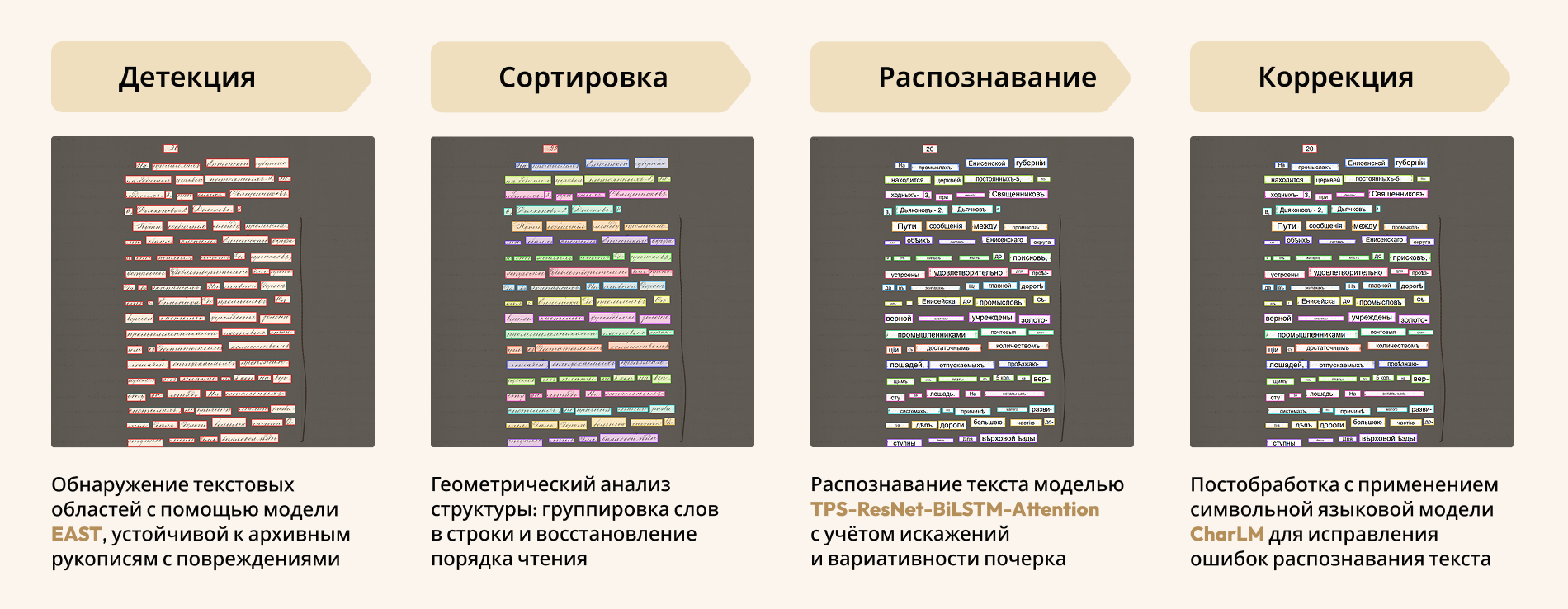
Сначала детектор (EAST) выделяет все текстовые области на рукописной странице. Затем модуль сортировки упорядочивает слова в строки, после чего сеть (TPS-ResNet-BiLSTM-Attention) считывает текст, а CharLM автоматически исправляет опечатки и дореформенную орфографию.
Фреймворк имеет открытый API, позволяющий интегрировать пользовательские модели на любом этапе OCR/HTR-пайплайна. Это обеспечивает высокую гибкость системы для быстрого прототипирования, тестирования и внедрения новых алгоритмов.
Ключевые метрики качества
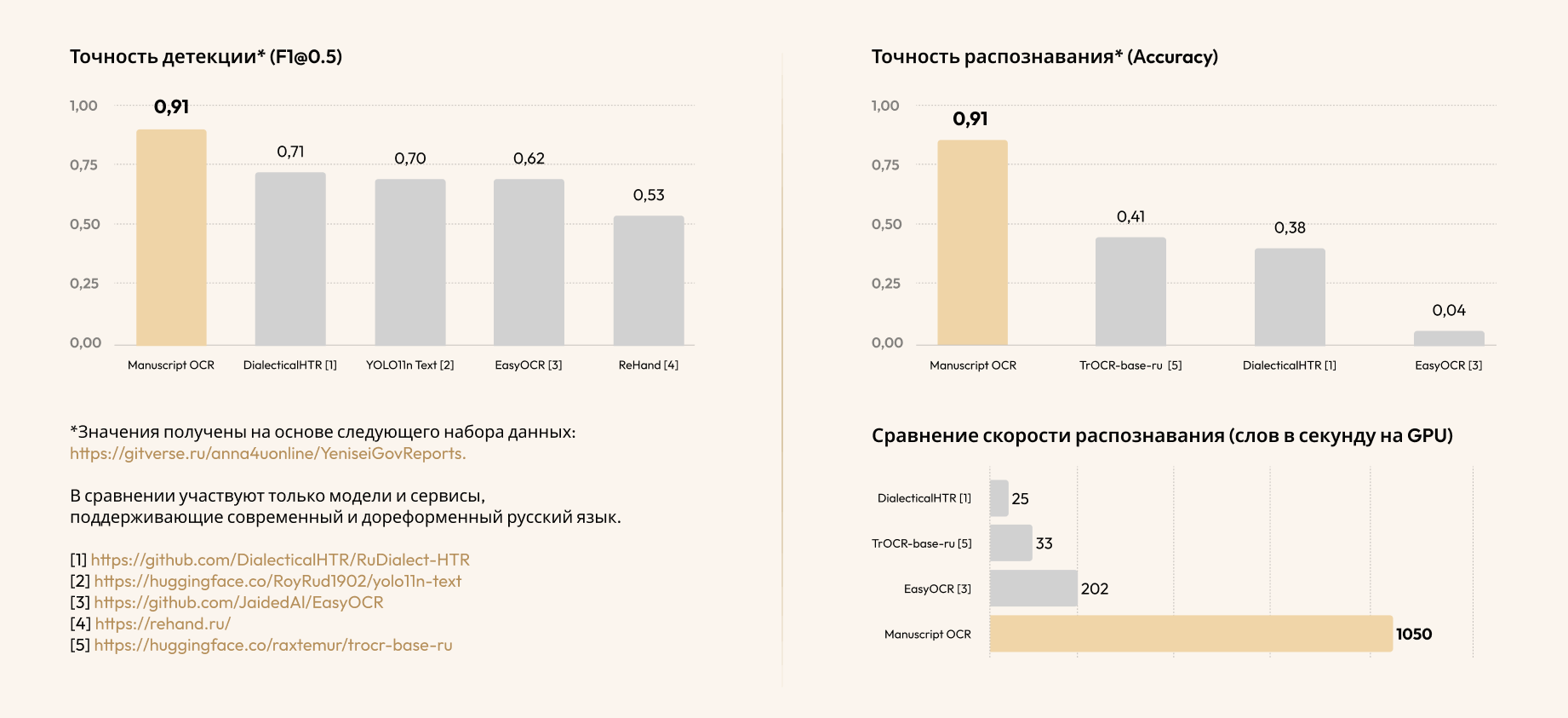
Manuscript OCR превосходит существующие решения по точности детекции и распознавания, при этом показывая более высокую скорость.
Кейсы
Создание крупнейших наборов данных для OCR/HTR дореформенных русских документов
Anno OCR — инструмент распознавания исторических рукописей и подготовки датасетов для обучения OCR
Практическое применение
Решение уже внедрено в программу Anno OCR и используется в Сибирском федеральном университете для задач распознавания и цифровизации исторических рукописных документов. Система применяется в образовательных и исследовательских проектах и уже используется более чем 200 пользователями для работы с архивными материалами и историческими источниками.
Решение может применяться для:
Оцифровки и распознавания дореформенных рукописных архивных материалов;
Интеграции в системы библиотек, архивов и музеев;
Образовательных и исследовательских проектов по историческим источникам;
Интеллектуальной обработки текста, включая интеграцию с LLM-системами для анализа и структурирования исторических документов.
Призер конкурса открытых проектов от GitVerse и Cloud.ru
2-е место в конкурсе «Код без границ» — https://habr.com/ru/specials/979702/
Публикация на Хабр (22 тыс. просмотров)
«Манускрипт. Распознать нельзя забыть: как мы научили нейросети читать рукописи XIX века» — https://habr.com/ru/articles/961062/
Связанные научные работы
Sherstnev, P.A.; Kozhin, K.D.; Pyataeva, A.V. Analyzing the Influence of Hyperparameters on the Efficiency of an OCR Model for Pre-Reform Handwritten Texts. Program Comput Soft 51, 173–180 (2025). https://doi.org/10.1134/S0361768825700069
Шерстнев, П. А.; Кожин, К. Д.; Пятаева, А. В. Анализ влияния гиперпараметров на эффективность OCR-модели для дореформенных рукописных текстов // Программирование. – 2025. – № 3. – С. 70-79. – DOI 10.31857/S0132347425030071. – EDN GRLAPG.
Шерстнев, П. А.; Кожин, К. Д.; Пятаева, А. В. Распознавание рукописных текстов отчетов губернаторов Енисейской губернии 19 века // GraphiCon 2024 : Материалы 34-й Международной конференции по компьютерной графике и машинному зрению, Омск, 17–19 сентября 2024 года. – Омск: Омский государственный технический университет, 2024. – С. 519-524. – DOI 10.25206/978-5-8149-3873-2-2024-519-524. – EDN GBEKEZ.
Письма поддержки

Проект реализован при поддержке гранта
Фонд содействия инновациям, конкурс «Код-ИИ», VII очередь
Полная документация - English & Русский
Публикация в соц. сети
Предпросмотр файлов
Файлы защищены автором
